Creating a new DL model
Accessing the DL Trainer and creating classes
Creating models is done in the Deep Learning Trainer panel. We can open this panel from the Analysis menu.
With the Deep Learning Training panel open we can define or rename the classes as we need them:
By default, there are 2 classes to start with a "Background" class and a "Class 1" object class. For a DL network we need to know both what the objects look like and what the background looks like. This allows us to annotate only portions of the image without needing to label every single class object on a plane. We can rename the object classes by double-clicking on the class name.
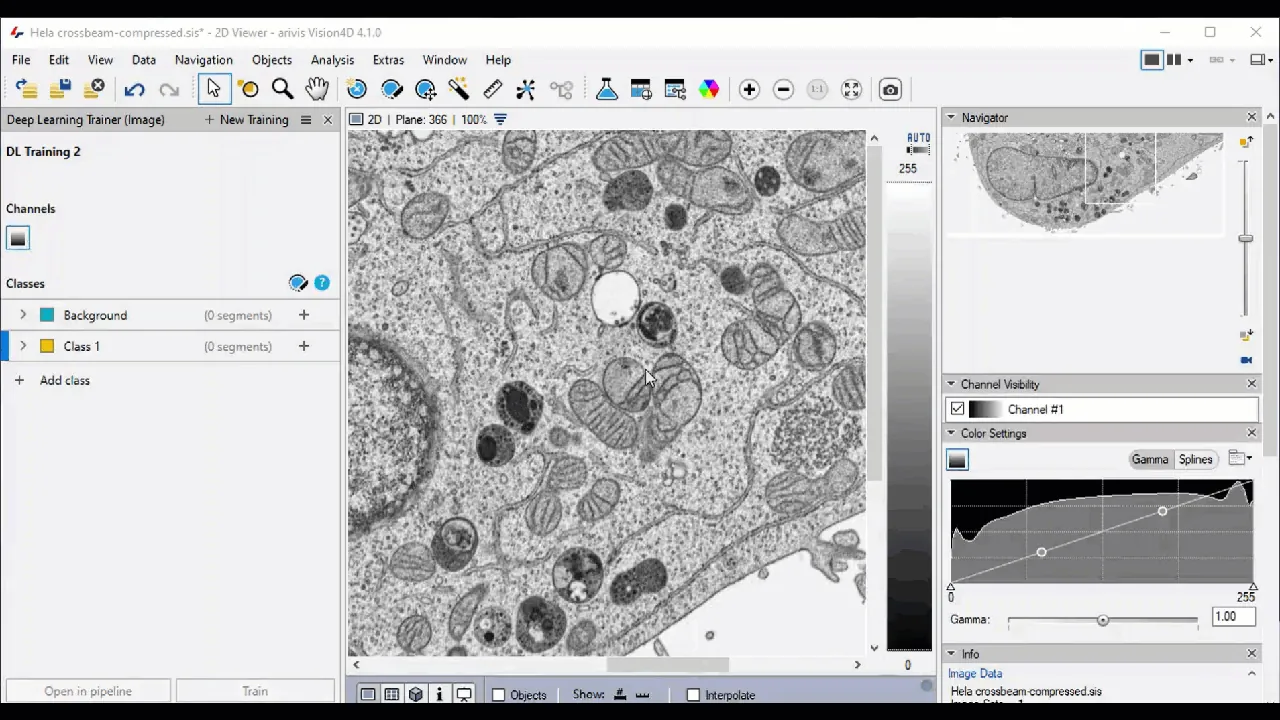
And we can add additional classes by clicking + Add Class.
Note that object classes cannot overlap, so if we want to be able to segment objects inside other objects it may be preferable to create multiple separate training for each individual object class.
Annotating objects
Training the network
Once we have annotated a sufficient number of class and background segments we can train the network by clicking the Train button at the bottom of the panel.
The trainer will initialize and start by asking the user to verify the training parameters:
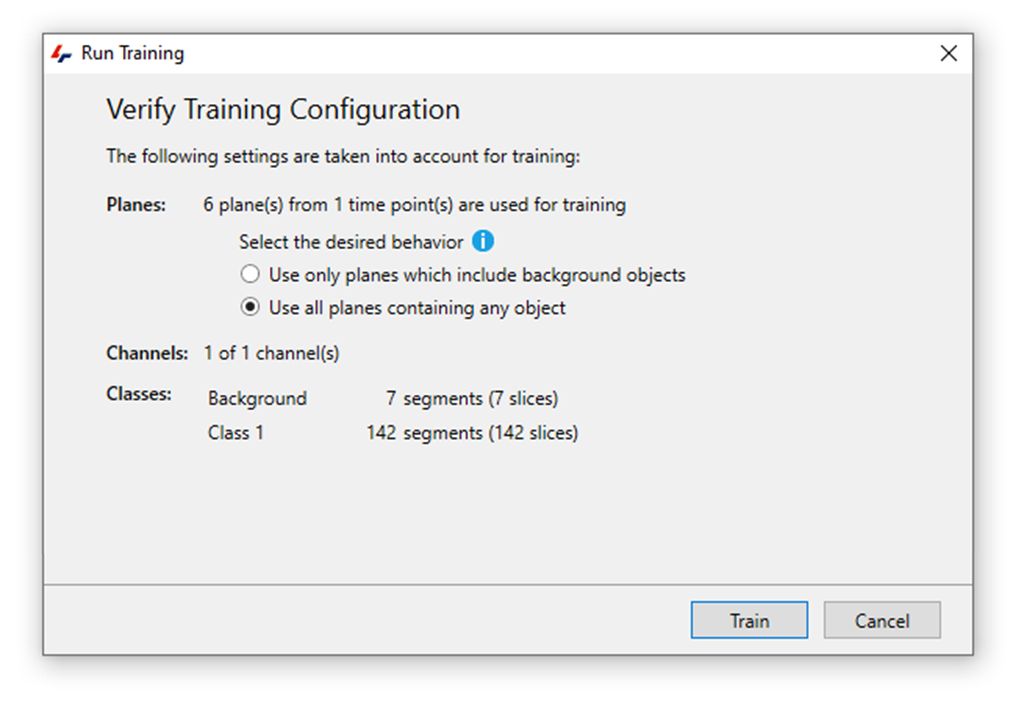
At this point, the software will show the total number of classes and objects in each class, and if there are only a few annotations for the objects class it will prompt you to return to the annotation task. In that case, if no further annotations are possible or if we just want to start with a small selection to get a preliminary result, we can proceed with the training or else return to providing ground truth annotations for better training.
If we want to proceed with the training, we can just press the Train button and, after a brief initialization process, the training will start.
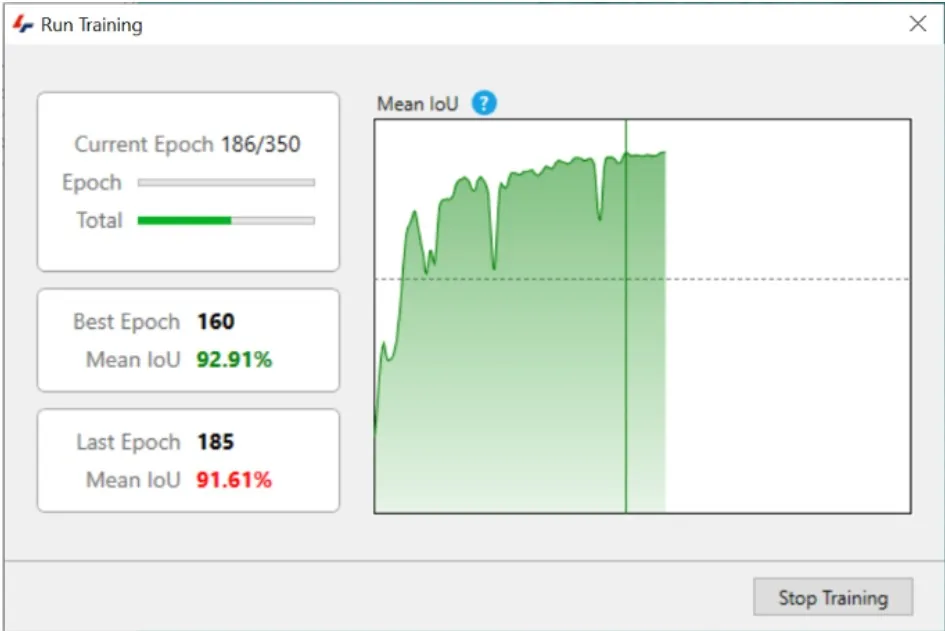
Note that the task of training the network can be very resource-intensive and time-consuming. It is generally best to allow for several hours in most cases, during which it is best not to rely on the computer, and especially the GPU, for any other tasks. Note that while the training is running it is not possible to use Vision4D.
When the training is complete, it results and error will appear in the training window:
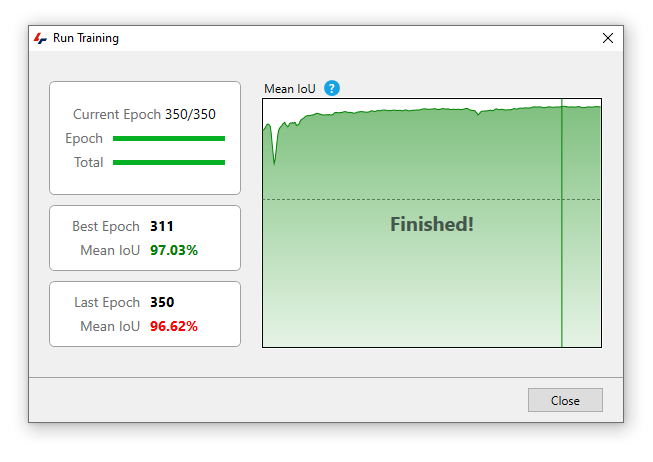
We can then use the trained network on our pipeline.